Data is the essence of most applications and this is particularly true for PLM. How you store the data is a key aspect of your PLM application. It will define how much data you can store, how it will scale, how fast you will be able to retrieve complex nested data, are you even able to find the information that might be of interest,… The selection of a single database engine comes with trade-offs. The selection of a single database prevent you from getting the best of multiple technologies and architecture,… unless… you do not just select a single database system.
Most of PLM already are based on multiple databases
Sometimes you may not know it but, whenever you have an advanced search engine, you are very likely to use a data store which will contain an index. Then multi data store technologies exists but is usually not much advertised with the selling point that different databases may server different use-cases within the same PLM context.
The DB engine types
You may have only work with relational database. SQL server or Oracle are the only engines you have worked with? Why would you use anything else? Well because we haven’t found one single architecture that excels in every context. Here is a list of all the database categories that exist out there:
[eckosc_column_container count=”two”]
[eckosc_column_item]
[/eckosc_column_item]
[eckosc_column_item]
[/eckosc_column_item]
[/eckosc_column_container]
Ranking database engines by popularity
This is one of the main information you can take from db-engines.com, the popularity of a database will give you some good information about how much people believe an engine is good and how much people could work and maintain the solution ecosystem.
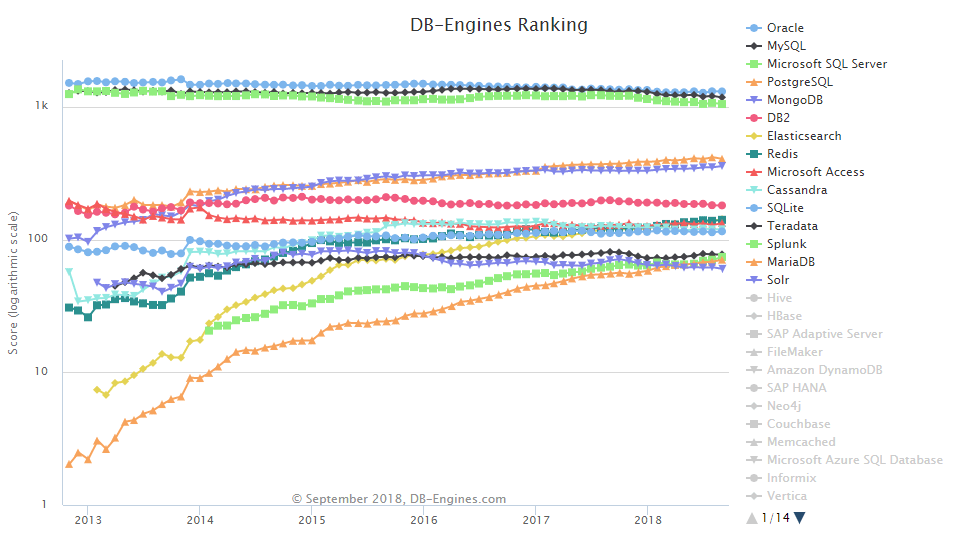

Local champions
After focusing on different database types and their best domain of expertise. Let’s focus on SQL and Graph champions
- SQL ranking :
- Oracle
- MySQL (owned by Oracle)
- Microsoft SQL Server
- Graph Databases (Graph only, not multi model)
- Neo4j
- Giraph
- JanusGraph
Mixing technologies?
So now you know you may have document index and SQL supporting your very inter-connected PLM environment, and you may be wondering how you could get value from a graph database. From what I have seen at Graphconnect, most of the usage of graph databases is more a BI and analysis usage. Companies have their data in a few systems that are usually storing data in SQL or document db and they create a big graph from this in Neo4j. By using the correct pipeline they can live update the data in the graph from the other system and enjoy the graph queries on fresh data. So this would be the first way to do it. I will detail in a future post the pros and cons of most database technologies to help you evaluate what tech might be of interest for storing your data.
Anyway, for now I just wanted to share with you this great website https://db-engines.com which allows you to stay in touch with the latest trends in database technologies.




